Lecture 07
第7讲学习讲义:Control of Gene Expression


对应课件:Lecture_7_Control_of_Gene_Expression.pdf
这一讲是整门课里最像“总控室”的一讲。前面你学过 DNA、RNA、蛋白质,现在要回答更难的问题:为什么同一个基因组,在不同细胞里会表现成完全不同的状态?
这讲的核心问题
- 为什么同一个个体的不同细胞长得和功能差别这么大?
- 基因转录是怎么被精确控制的?
- DNA 结合蛋白如何识别特定序列?
- 基因开关怎样整合多个输入?
- 转录后层面还有哪些调控?
一、同一个基因组,为什么能产生不同细胞类型
课件开头强调:不同细胞在结构和功能上差别极大,但分化细胞通常仍保留完整基因组。
这件事的意义是:
- 细胞分化通常不是靠“丢掉不用的基因”。
- 而是靠“选择性表达不同基因”。
这也是克隆动物和核移植实验能成立的逻辑基础:
- 即使是已分化细胞的细胞核,仍保留生成完整个体的遗传信息。
二、不同组织为什么有不同表达谱
课件展示了不同组织和肿瘤的表达模式差异。
你可以把 expression pattern 理解成:
- 某个细胞此刻“打开了哪些基因,关闭了哪些基因”。
这决定了:
- 细胞做什么工作。
- 它分泌什么蛋白。
- 它对什么信号敏感。
- 它的代谢方式如何。
典型规律是:
- 每个细胞并不会表达全部基因。
- 而是只表达与其身份和状态相关的一部分。
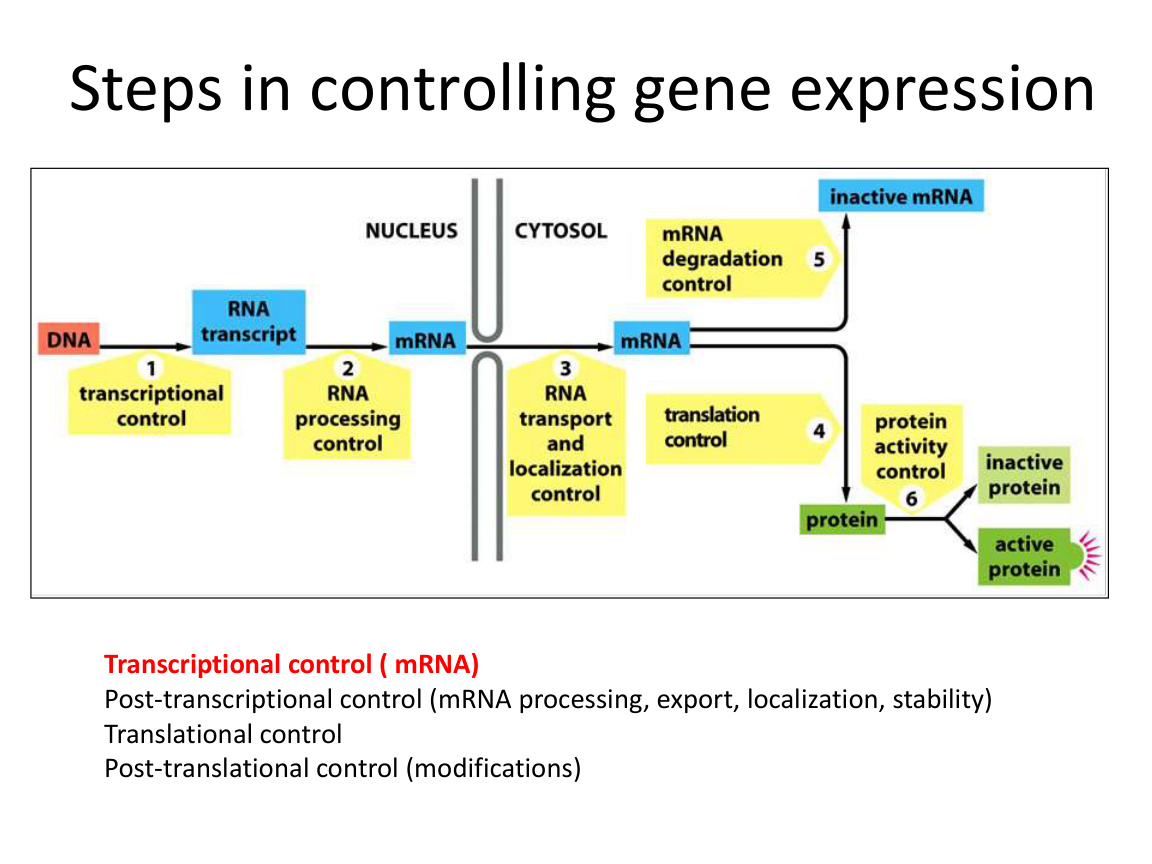
三、基因表达可以在哪些层面被控制
这点非常重要,因为很多同学一看到“gene expression control”就只想到转录。
实际上可控制的层面很多:
- 染色质开放程度。
- 转录起始频率。
- RNA 剪接方式。
- RNA 输出。
- RNA 稳定性。
- 翻译效率。
- 蛋白质稳定性和活性。
课件虽然重点放在转录和转录后调控,但你脑子里一定要有全景图。
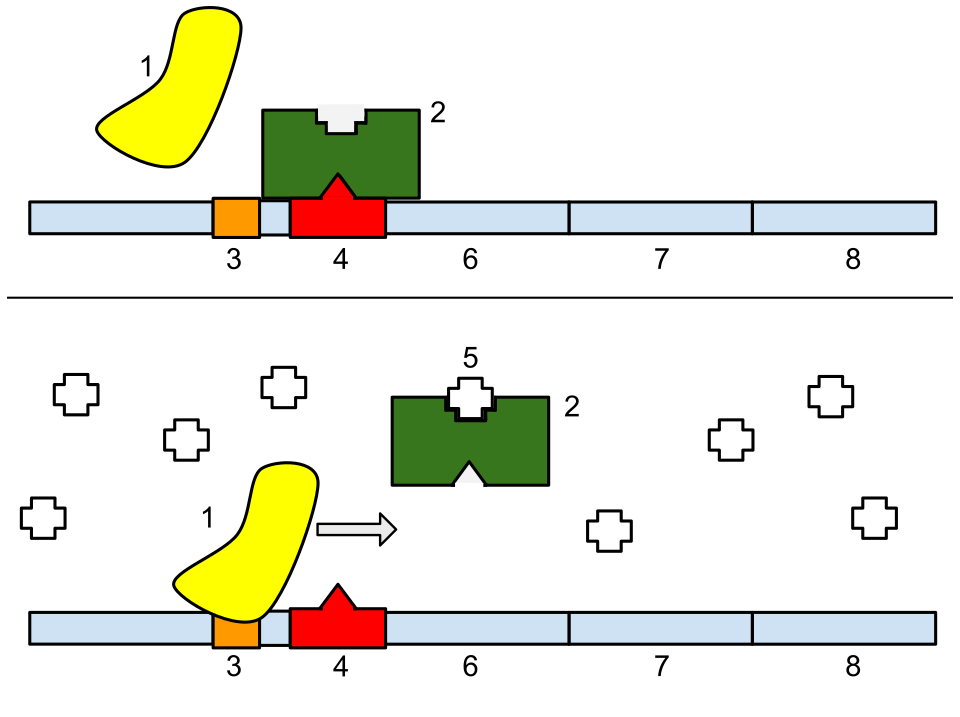
四、DNA 结合蛋白如何识别特定序列
课件讲到 direct contact between DNA and protein involves hydrogen bonds 等内容。
核心思想是:
- 蛋白不是把 DNA 全拆开来看碱基。
- 它通常通过 DNA 大沟暴露出的化学特征来识别序列。
识别依赖:
- 氢键。
- 静电相互作用。
- 形状互补。
- DNA 局部弯曲性和结构特征。
五、常见 DNA 结合结构基序 motifs
这部分是考试爱考的分类题,你要做到“能认、能说用途”。
1. Helix-turn-helix,HTH
特点:
- 两个螺旋通过一个转角连接。
- 其中一个识别螺旋插入 DNA 大沟。
常见于:
- 细菌调控蛋白。
- 一些发育调控蛋白。
2. Homeodomain
它本质上属于 helix-turn-helix 相关家族,但在发育生物学中特别重要。
意义:
- 参与胚胎模式建立和细胞命运决定。
3. Zinc finger
锌指的核心不是“锌负责直接识别 DNA”,而是:
- 锌离子帮助稳定特定折叠结构。
- 稳定后由蛋白特定表面与 DNA 接触。
锌指蛋白常见于真核调控蛋白。
4. Leucine zipper
亮氨酸拉链主要帮助:
- 二聚化。
二聚化后,附近的 DNA 结合区才能更稳定地与 DNA 结合。
5. Helix-loop-helix,HLH
特点:
- 螺旋之间由 loop 连接。
- 常与二聚化和发育调控相关。
6. 其他基序
课件还提到 β-sheet、loops 等。你不用机械背所有形状,但要理解:
- 不同蛋白可以用不同结构策略实现 DNA 识别。
六、如何找出调控蛋白和它的结合位点
课件列出了一系列实验方法,这些方法非常常见。
1. EMSA,gel mobility shift assay
原理:
- DNA 和蛋白结合后,复合物在胶上迁移更慢。
用途:
- 判断蛋白是否和某段 DNA 结合。
2. DNA affinity chromatography
用途:
- 用已知 DNA 序列去“钓”能结合它的蛋白。
3. DNA footprinting
用途:
- 精细定位蛋白结合在 DNA 的哪一段。
思路:
- 蛋白盖住的区域不容易被切割,因此留下“脚印”。
4. ChIP,chromatin immunoprecipitation
用途:
- 在细胞真实染色质环境中检测某蛋白是否结合某段 DNA。
这是把“体外结合”推进到“体内结合证据”的关键技术。
5. Phylogenetic footprinting
用途:
- 通过跨物种保守序列推测调控元件。
理由是:
- 真正重要的调控位点更可能在进化中被保留下来。
七、遗传开关 genetic switch:基因不是连续开,而是受逻辑控制
1. 细菌简单开关
细菌中常见:
- 一个环境信号影响抑制子或激活子。
- 决定某一组基因是否转录。
这类系统像最基础的 if-else 逻辑。
2. 多输入整合
更复杂的基因开关会同时读取多个信号,例如:
- 营养状态。
- 应激状态。
- 发育位置。
最终只有在特定组合条件下才开启目标基因。
八、抑制子和激活子怎么工作
1. Repressor 抑制子
作用:
- 降低转录概率。
方法可能包括:
- 阻止聚合酶结合。
- 阻止转录起始复合体组装。
- 招募染色质沉默因子。
2. Activator 激活子
作用:
- 提高转录概率。
方法可能包括:
- 招募转录机器。
- 招募染色质重塑和组蛋白修饰酶。
- 稳定启动复合体。
3. 同一个蛋白可能既能激活也能抑制
这取决于:
- 它结合的位置。
- 搭配的辅因子。
- 当前细胞环境。
九、DNA looping:为什么远处元件也能控制基因
DNA 不是一根永远拉直的棍子,而是可弯曲、可折环。
因此:
- 远处的调控元件可以通过成环接近启动子。
- 不同蛋白之间可以通过 DNA 空间折叠相互作用。
这在真核基因调控里尤其常见。
十、真核基因调控比细菌复杂在哪里
课件强调 eukaryotic gene regulation versus prokaryotic regulation。
真核更复杂的原因包括:
- DNA 被染色质包装。
- 调控元件可远距离作用。
- 细胞类型多,发育阶段多。
- 同一基因常整合多个输入。
典型真核调控区可能包括:
- 核心启动子。
- 近端调控元件。
- 增强子 enhancer。
- 沉默子 silencer。
- 染色质边界元件。
十一、真核激活蛋白如何改变局部染色质
课件列出四种 ways activator proteins can direct local alterations in chromatin。
你可以归纳为几类:
- 招募组蛋白乙酰转移酶等修饰酶,让染色质更开放。
- 招募 ATP 依赖染色质重塑复合物。
- 促进通用转录因子和 RNA Pol II 组装。
- 招募 Mediator 等桥接因子。
Histone acetylation 为什么常和转录活跃相关
因为乙酰化常减少组蛋白尾部正电特征,削弱其与 DNA 的紧密结合,并有利于招募特定 reader 蛋白。
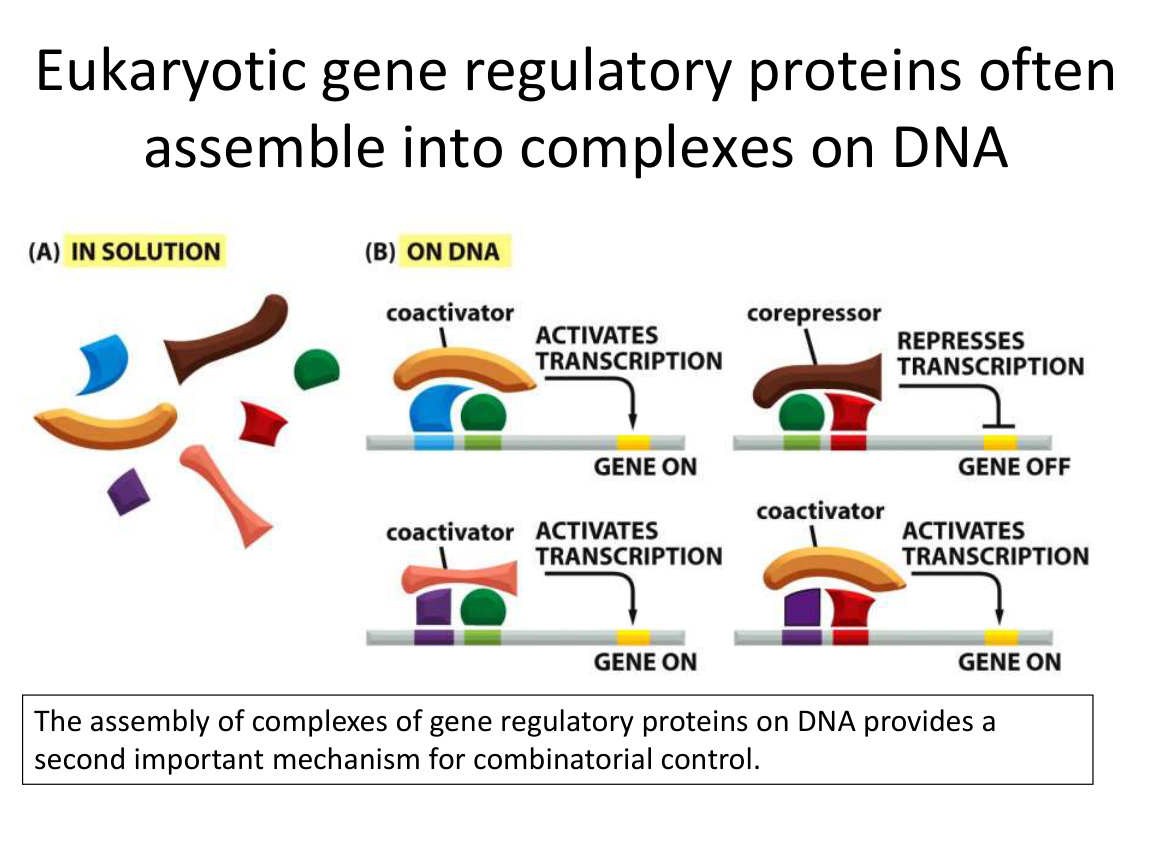
十二、协同作用 synergy:多个弱调控合起来变强
转录调控常不是某一个因子单独决定,而是多个因子协同。
这使系统具有:
- 更高特异性。
- 更强组合编码能力。
- 对多种输入的整合能力。
十三、组合调控 combinatorial control:复杂性的真正来源
课件中 eve 基因条纹表达是经典例子。
核心思想是:
- 不同区域有不同调控蛋白浓度组合。
- 同一个基因只在特定组合条件下被激活。
这非常像电路逻辑:
- 不是单一开关,而是多输入逻辑门。
这也是为什么有限数量的调控蛋白可以产生极其复杂的表达模式。
十四、细胞类型如何被稳定维持:反馈和调控回路
1. 正反馈 positive feedback
如果某个调控因子能促进自身表达,就可能形成稳定开态。
意义:
- 帮助细胞“记住”某种身份。
2. 转录回路 circuits
多个因子彼此激活或抑制,可以形成:
- 双稳态。
- 顺序表达。
- 发育程序。
因此细胞命运不是简单一条直线,而是调控网络的稳定状态。
十五、DNA 甲基化与 CpG islands
1. DNA methylation
DNA 甲基化常与基因沉默相关,尤其在真核调控和表观遗传中很重要。
2. CpG islands
CpG islands 是富含 CpG 位点的区域,常位于基因启动子附近。
它们的甲基化状态常影响:
- 启动子是否容易被激活。
- 基因是否处于沉默状态。
十六、基因组印记 genomic imprinting
这是一类很容易考概念理解的问题。
它的关键不是“基因被删除”,而是:
- 来自父方和母方的等位基因可能因为甲基化等表观遗传标记不同,而表现出不同表达状态。
因此某些基因只表达父源版本,或只表达母源版本。
十七、X 染色体失活
在雌性哺乳动物中,两条 X 染色体如果都完全活跃,表达剂量会失衡。
因此会发生:
- 一条 X 染色体被整体沉默。
这说明表观遗传调控可以在非常大尺度上发生。
十八、转录后调控:表达控制并没有在转录结束后停下
课件最后一大部分讲的就是 post-transcriptional control。
1. Transcription attenuation
常见于原核,指的是:
- 转录过程本身在早期就被调节是否继续延长。
2. Riboswitch
某些 RNA 自身可结合小分子并改变构象,从而影响转录或翻译。
这说明 RNA 不只是被动中间体,也可以直接感知环境。
3. Alternative splicing
不同剪接方式可产生不同 mRNA,从而让一个基因产生多种蛋白。
4. 终止位点或 poly(A) 位点选择
不同 3' 端形成方式会改变:
- mRNA 稳定性。
- 翻译效率。
- 调控元件长度。
5. RNA editing
RNA 序列在转录后还可被修改,导致与 DNA 模板不完全一致。
6. RNA nuclear export
哪些 RNA 能出核、何时出核,也是调控。
7. mRNA localization
mRNA 可以被运送到细胞特定位置后再翻译,这对细胞极性和发育很重要。
8. mRNA stability
同样的转录速率下,mRNA 半衰期不同,会造成表达量明显差异。
9. Translational control
即使 mRNA 已存在,也不一定马上被高效翻译。
调控方式包括:
- 起始因子活性改变。
- 5'UTR / 3'UTR 上调控位点作用。
- IRES 等特殊起始方式。
十九、UTR 为什么重要
未翻译区 untranslated regions 并不是没用。
它们常包含:
- RNA 结合蛋白识别位点。
- miRNA 结合位点。
- 影响翻译效率和稳定性的顺式元件。
二十、miRNA 和 RNAi:RNA 也能“沉默别人”
1. miRNA
miRNA 是短小调控 RNA,通常通过与目标 mRNA 配对来:
- 抑制翻译。
- 促进降解。
2. P-body
Processing body 是 mRNA 被储存、降解或沉默处理的重要场所之一。
3. RNA interference,RNAi
RNAi 可作为防御机制,也被细胞利用来调控基因表达。
它说明:
- RNA 可以参与序列特异性的沉默过程。
二十一、把这一讲串成一句话
同一个基因组之所以能产生不同细胞类型,是因为基因表达在转录前、转录中、转录后乃至翻译阶段都受到精细控制;其中 DNA 结合蛋白、染色质状态、组合式遗传开关以及 miRNA 等转录后机制共同构成了细胞命运和功能的调控网络。
二十二、常见误区
- “不同细胞不同,是因为它们 DNA 不一样”通常不对,关键差异主要在表达程序。
- “基因调控就是转录因子绑定启动子”太简单,真实系统包含染色质、远端元件和多层后续调控。
- “UTR 不编码蛋白,所以不重要”是错的。
- “miRNA 只是降解 RNA”不完整,它也可抑制翻译并影响稳定性。
- “表观遗传只和 DNA 甲基化有关”太窄。
二十三、你必须会的关键词
- Gene expression pattern:基因表达谱。
- Transcription factor:转录因子。
- HTH / Homeodomain / Zinc finger / Leucine zipper / HLH:常见 DNA 结合基序。
- EMSA:凝胶迁移率变动实验。
- Footprinting:DNA 足迹分析。
- ChIP:染色质免疫沉淀。
- Enhancer:增强子。
- Combinatorial control:组合调控。
- Positive feedback:正反馈。
- DNA methylation:DNA 甲基化。
- CpG island:CpG 岛。
- Genomic imprinting:基因组印记。
- Alternative splicing:可变剪接。
- miRNA:微小 RNA。
- RNAi:RNA 干扰。
二十四、自测题
1. 为什么同一个体不同细胞会有完全不同表型?
答题关键:
- 基因组基本相同,但表达谱不同。
2. DNA 结合蛋白如何识别特定序列?
答题关键:
- 通过大沟中的化学特征、氢键、静电和形状互补。
3. 组合调控为什么能大幅增加系统复杂度?
答题关键:
- 不同因子组合可产生大量逻辑状态和空间模式。
4. CpG 岛和基因组印记分别反映了什么调控思想?
答题关键:
- DNA 甲基化影响表达。
- 父母来源不同可导致表达差异。
5. 转录后调控至少举出四种方式。
答题关键:
- 剪接、RNA 编辑、核输出、定位、稳定性、翻译控制、miRNA 等。
二十五、考前速记版
- 不同细胞的差异主要来自不同基因表达程序。
- DNA 结合蛋白通过特定结构基序识别特定 DNA 序列。
- 真核基因调控高度依赖增强子、染色质和组合调控。
- 正反馈和调控回路帮助稳定细胞命运。
- DNA 甲基化、印记和 X 失活体现表观遗传控制。
- 表达控制在转录后仍继续,包括剪接、稳定性、翻译和 miRNA 调控。
二十六、深入扩展:增强子、启动子和转录因子到底怎么配合
很多同学会背 enhancer 和 promoter,但真正答题时说不清它们的分工。
启动子 promoter 更像“基础起跑线”
它的核心作用是:
- 定义转录起始位置附近的基础装配区域。
- 让通用转录机器有地方组装。
增强子 enhancer 更像“远程调度台”
它的核心作用是:
- 结合特定调控蛋白。
- 提高某个基因在特定条件下被转录的概率。
- 能在相对较远距离发挥作用。
为什么增强子可以离基因很远还起作用
因为 DNA 可以形成 loop,把远处增强子和启动子空间上拉近。
所以基因调控不是按“线性距离”理解,而要按“三维空间接触”理解。
二十七、DNA 结合基序为什么常和二聚化有关
像 leucine zipper 和 HLH,不仅是 DNA 识别结构,也是蛋白-蛋白相互作用平台。
为什么二聚化很有用
- 增加结合稳定性。
- 提高识别特异性。
- 允许不同亚基组合,形成更多调控逻辑。
例如:
- A 和 A 形成同源二聚体。
- A 和 B 形成异源二聚体。
这两种组合即使都绑定相似 DNA 区域,也可能招募不同辅因子,产生不同输出。
这就是“有限数量调控蛋白也能组合出巨大复杂度”的一个分子基础。
二十八、为什么不存在一个简单的 DNA 识别氨基酸密码表
课件问过这个问题。答案是:通常不存在那种像遗传密码那样简单的一一对应关系。
原因包括:
- 蛋白与 DNA 识别依赖整体三维结构,不只依赖单个氨基酸。
- 一个氨基酸残基是否与 DNA 碱基接触,要看空间位置。
- 同一序列可能通过不同骨架构型来识别。
- 识别还涉及 DNA 弯曲性和局部形状。
所以 DNA 识别是“结构和化学的上下文问题”,不是纯线性配码问题。
二十九、为什么真核调控特别强调 chromatin context
对细菌来说,DNA 大多更直接暴露;对真核来说,DNA 常被核小体包裹。
因此一个转录因子想发挥作用,先得回答一个前提问题:
- 目标位点此刻是否可被访问。
这就使真核调控天然多了一层:
- 染色质状态决定“能不能接近”。
- 转录因子和辅因子再决定“接近之后做什么”。
三十、什么叫 pioneer factor 先锋因子
虽然课件没有专门展开这个词,但理解真核调控时很有帮助。
先锋因子可以粗略理解为:
- 一类更擅长在相对封闭染色质中先占位的调控蛋白。
- 它们的结合可能为后续更多因子的进入创造条件。
你可以把它看作“先把门撬开的人”。
三十一、转录协同 synergy 为什么不是简单相加
如果两个激活子各自都能提高一点转录水平,它们一起时有时会提升远超相加值。
这是因为它们可能同时完成不同工作:
- 一个负责开染色质。
- 一个负责招募转录机器。
- 一个负责稳定 enhancer-promoter loop。
所以协同的本质是:
- 多个步骤共同受益,而不是同一步骤重复加码。
三十二、Eve 条纹为什么是组合调控经典案例
因为它非常直观地说明:
- 同一个基因在胚胎不同位置接收到不同调控蛋白浓度组合。
- 只有某些组合满足条件时,基因才在那个位置表达。
这说明发育图案不是“一个基因一种位置”,而是:
- 同一个基因通过不同调控模块读取不同空间信息。
三十三、为什么正反馈能让细胞“记住”身份
正反馈的本质是:
- 某因子越高,越促进自身或同一程序维持。
这样一来,哪怕最初只是一个短暂信号,一旦跨过阈值,就可能把系统推入稳定状态。
这对细胞分化非常关键,因为发育不能总依赖最初信号持续存在,细胞必须能“自我维持”某种身份。
三十四、X 染色体失活为什么是表观遗传的经典模型
因为它同时满足表观遗传的几个关键特征:
- 不改变 DNA 序列。
- 却大范围改变染色体活性。
- 能在细胞分裂后稳定维持。
它说明:
- 基因调控不一定只发生在单个基因水平。
- 也可以发生在整条染色体尺度。
三十五、为什么 DNA methylation 常与长期沉默相关
相较于某些瞬时转录因子结合事件,DNA 甲基化更适合承担“较稳定状态标记”。
原因包括:
- 可在复制后通过相关机制被维护。
- 可影响特定蛋白是否能结合启动子区域。
- 可招募抑制性染色质复合物。
所以 DNA methylation 常和长期沉默、细胞记忆、印记等现象联系在一起。
三十六、miRNA 是怎么生成的
课件提到 miRNA,但如果你想真正理解它怎么调控,最好再补一下生成过程。
粗略流程可记为:
1. 先转录成较长初级转录本 pri-miRNA。 2. 在细胞核中加工成前体 pre-miRNA。 3. 输出到细胞质。 4. 再被加工成短双链 RNA。 5. 其中一条链装载进 RISC 复合体。 6. 引导复合体去识别靶 mRNA。
miRNA 为什么常结合 3'UTR
因为 3'UTR 是调控信息富集区域,而且不直接改变蛋白编码序列,更适合作为调控平台。
三十七、miRNA 配对不一定要求完全匹配
这是它和某些 RNAi 场景的重要差异。
很多动物 miRNA 只需要“种子区”较好匹配,就能:
- 抑制翻译。
- 加速 mRNA 去腺苷酸化和降解。
这让一个 miRNA 常常能够调控一批相关 mRNA,而不是只盯住一个靶标。
三十八、mRNA 稳定性为什么是表达量的重要变量
你可以把一个基因的最终 RNA 水平粗略看成两个因素共同决定:
- 生产速度有多快。
- 降解速度有多快。
因此两个基因即使转录速率差不多,只要稳定性不同,最终丰度也可能差很多。
这就是为什么 AU-rich elements、miRNA 位点、RNA 结合蛋白等都能深刻影响表达结果。
三十九、为什么很多调控最后都集中到 translation initiation
因为一旦起始成功,后续延长通常比较顺。
所以控制起始往往是成本最低、收益最高的调控点。细胞可通过改变:
- 起始因子磷酸化状态。
- cap 依赖招募效率。
- UTR 上阻遏结构。
- IRES 使用情况。
来快速响应环境变化。
四十、如果考试问“细胞分化为什么稳定”,可以怎么答
推荐思路:
1. 不同细胞表达不同转录因子组合。 2. 转录因子通过正反馈和互相抑制形成稳定网络。 3. 染色质状态和 DNA 甲基化帮助维持长期沉默或激活。 4. miRNA 和转录后机制进一步清除不符合该细胞身份的转录本。
这样就把转录、表观遗传和转录后调控都串起来了。